After finding that multilingual models misread Norwegian queries, we reached out to the National Library of Norway. Their model finds The Scream. It also reveals a trade-off worth understanding.
Background
In an earlier post, I described a finding from our semantic search pilot: searching for “redsel” (dread) returned red paintings. The multilingual embedding models we tested — from Google, OpenAI, and Voyage — all read Norwegian as a thin signal layered over English surface text.
The problem was not the image descriptions. It was the bridge between a Norwegian query and Norwegian meaning in the embedding space.
After publishing that finding, I contacted the National Library of Norway (Nasjonalbiblioteket).
NbAiLab and nb-sbert-v2-large
The National Library runs an AI lab, NbAiLab, which develops language models built on Norwegian text. Their latest sentence embedding model, nb-sbert-v2-large, is fine-tuned from nb-bert-large, a BERT-based model trained on the library’s own digitised collections.
Key properties:
- Trained on Norwegian text, with cross-lingual alignment to English
- 1024-dimensional dense vector space
- Maximum sequence length of 512 tokens
- Apache 2.0 licence, hosted on Hugging Face
- Trained and hosted within the EU
The model is designed so that semantically similar sentences in Norwegian and English sit close to each other in the embedding space. An English-Norwegian sentence pair should have high cosine similarity.
What happened when I tested it
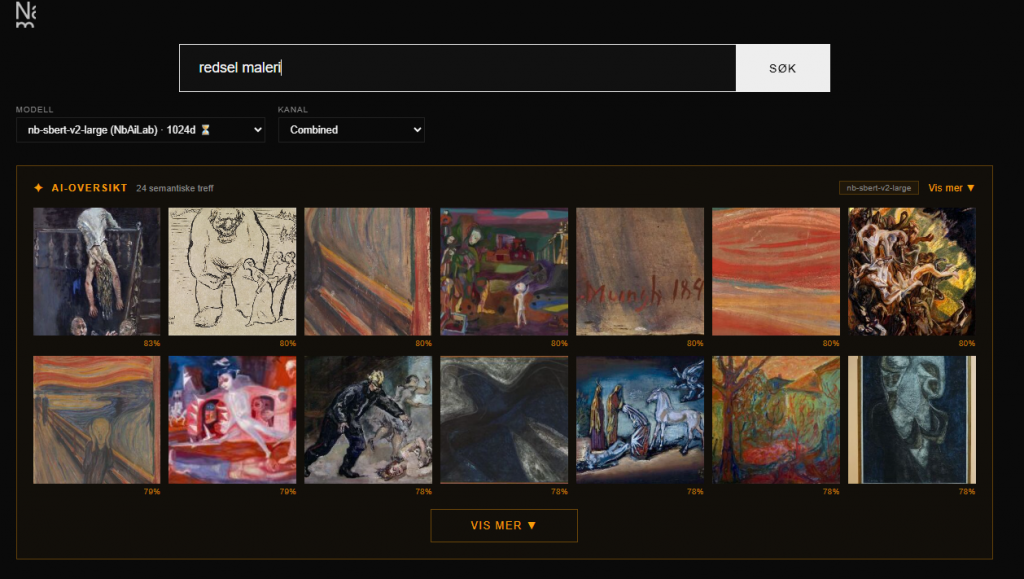
I searched for “redsel”.
Among the results: The Scream by Munch.
That is exactly what should happen. The multilingual models did not get there. A model trained on Norwegian text, by an institution that digitised Norwegian books and newspapers, understood what “redsel” means.
The finding from the previous article pointed toward a specific gap in the pipeline. This is a direct response to that gap.
The trade-off
The improvement in Norwegian comes with a cost.
Searching for “man’s best friend” returned no dogs. “Ship of the desert” returned no camels. These are the same idiom tests that multilingual models handle well. The NbAiLab model, trained to understand Norwegian deeply, understands English less broadly.
This is not a surprise. I was warned about it directly. A model optimised for one language trades coverage for precision.
The boundary is clear in practice: the model works when the user thinks and searches in Norwegian. Searching in English, or using English idioms, the multilingual models still outperform it.
Searching “menneskets beste venn” returns dogs. The understanding is there. It is language-specific.
Where this fits in our testing
We are currently evaluating several embedding models in parallel: models from OpenAI, Voyage, Google, and now NbAiLab. Each has different strengths. BGE-M3, which we use in the current pilot, handles multilingual queries and cross-lingual retrieval well. The NbAiLab model handles Norwegian meaning more precisely.
No final architecture decision has been made. What the tests suggest is that the two approaches are complementary rather than competing. A Norwegian model as a dedicated Norwegian-query channel, alongside multilingual coverage, is the architecture that makes sense from what we have seen so far.
The choice of embedding model is not neutral. For a Norwegian cultural heritage collection, a model trained on Norwegian text produces qualitatively different results — not just marginally better ones.
A note on the collaboration
The National Library’s AI lab built this model from digitised collections at a memory institution, for exactly the kind of use case we are working on. That work is directly relevant to ours. We are in dialogue about how it might be used in the collection going forward.
Read the previous article: When the machine read “redsel” as red.
nb-sbert-v2-large is available on Hugging Face under Apache 2.0.